文章目录
在使用正则表达式的时候,会遇到需要精准匹配某些字符的情况,这时候 \b \B 就派上用场了。若是不理解这两个正则表达式元字符,用起来便不会得心应手。本文介绍如何使用它们。
| 元字符 | 含义 |
|---|---|
| \b | 匹配一个单词边界 |
| \B | 匹配一个非单词边界 |
| \w | 匹配一个字母、数字或下划线。等价于 [A-Za-z0-9_] |
这两个元字符的含义看起来非常官方,但却又非常准确。理解之后就会发现它们概括的言简意赅,一点废话都没有,但却需要细细品味。
要想理解这两个元字符,需要明确两个概念:
- 单词:说到单词,又涉及到一个元字符
\w,如上表所述,\w表示一个字母数字或下划线。而单词,正是由若干\w组成的,也就是任意字母数字的组合。 - 边界:在正则表达式里面,边界不是特定的字符,而是一个不存在的东西,一个概念。可以说是\b \B代表的东西,边界是任何两个字符之间的那个东西。
明确这两个概念之后,下面就可以说明 \b \B 代表的含义了。
- \b 单词边界:匹配一个边界,一边字符是\w,一边字符不是\w
- \B 非单词边界:匹配除 \b 之外的边界。两边字符都是\w,或两边字符都不是\w
这里先下一个定义,用正则表达式的语言表达:
- 字符是\w:
\w - 字符不是\w:
[^\w]
如下图所示,图中所有虚竖线都是边界。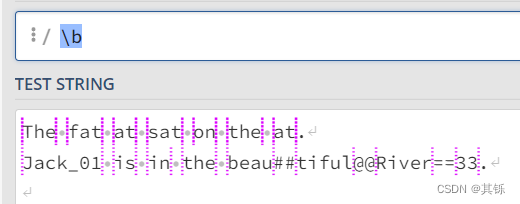
上图中,每个边界都满足:一边是\w,一边是[^\w]。即:
- 左边是
\w,右边是[^\w] - 左边是
[^\w],右边是\w
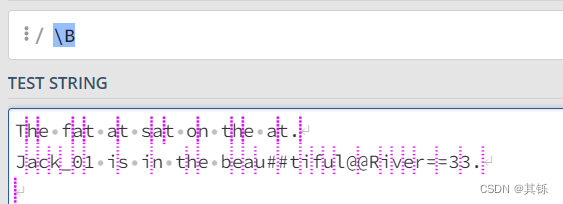
\B 就是除 \b 之外的所有边界。\b表示一边是\w,一边是[^\w]的边界,那么取反,即:
- 两边都是
\w - 两边都是
[^\w]
简言之:
| 边界类型 | 左侧字符 | 右侧字符 |
|---|---|---|
| \b | \w | [^\w] |
| \b | [^\w] | \w |
| \B | \w | \w |
| \B | [^\w] | [^\w] |
用字符是 \w 代表 1,字符是[^\w]代表 0,那么用计算机的逻辑思维理解就是:
| 边界类型 | 左侧字符 | 右侧字符 |
|---|---|---|
| \b | 1 | 0 |
| \b | 0 | 1 |
| \B | 1 | 1 |
| \B | 0 | 0 |
两个二进制数的表示也就这四种情况。因此,可得到如下结论:
- \b 代表的边界,左右字符类型不相同
- \B 代表的边界,左右字符类型相同
注意:这里指的字符类型只包括两种(是\w 、不是\w)。其它都可以忘掉,只要记住这两个结论就可以了。
看到这,应该能从上面的图表中理解什么是单词边界\b,什么是非单词边界\B了。
这里根据第1节得出的结论:
- \b 代表的边界,左右字符类型不相同
- \B 代表的边界,左右字符类型相同
结合几个示例进行分析。
2.1 简单示例
2.1.1 示例1
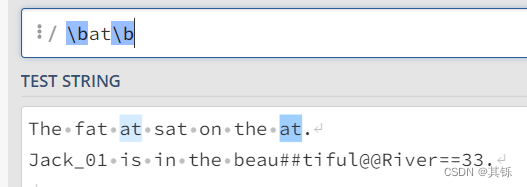
对于模式\bat\b中的第一个\b,由于其右侧是\w,那么其左侧必须是[^\w];
对于模式\bat\b中的第二个\b,由于其左侧是\w,那么其右侧必须是[^\w];
因此匹配结果如图所示。
2.1.2 示例2
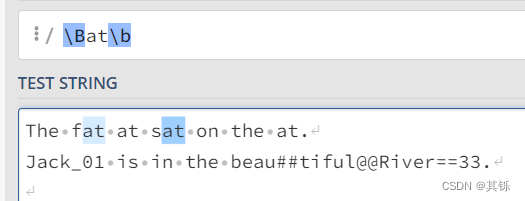
对于模式\Bat\b中的\B,由于其右侧是\w,那么其左侧也必须是\w;
对于模式\Bat\b中的\b,由于其左侧是\w,那么其右侧必须是[^\w];
因此匹配结果如图所示。
2.1.3 示例3
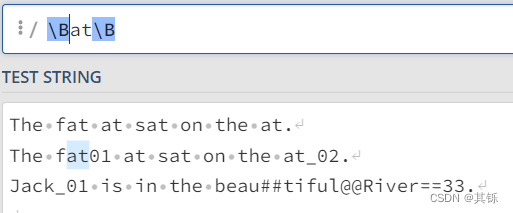
对于模式\Bat\B中的第一个\B,由于其右侧是\w,那么其左侧也必须是\w;
对于模式\Bat\B中的第二个\B,由于其左侧是\w,那么其右侧也必须是\w;
因此匹配结果如图所示。
2.1.4 示例4
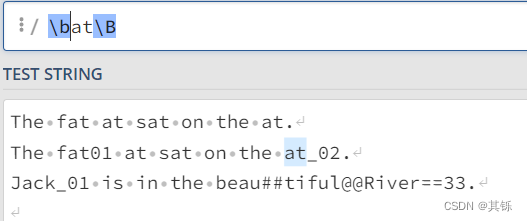
对于模式\bat\B中的\b,由于其右侧是\w,那么其左侧必须是[^\w];
对于模式\bat\B中的\B,由于其左侧是\w,那么其右侧也必须是\w;
因此匹配结果如图所示。
2.2 复杂示例
能看懂上面的简单示例的话,理解下面的就不难了。
2.2.1 示例5
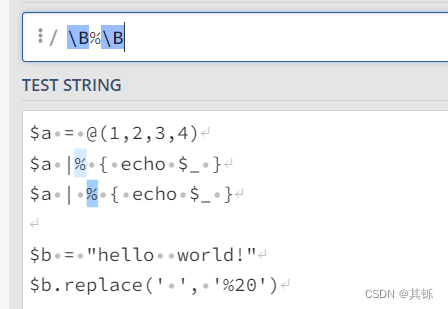
由于%是[^\w],因此匹配结果两侧的字符也应该是[^\w]
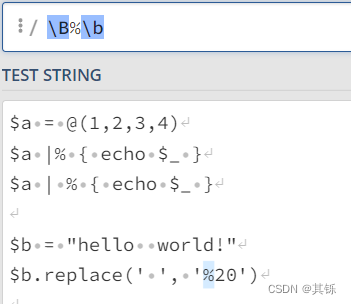
这个不用说应该就能懂了。
2.2.2 示例6
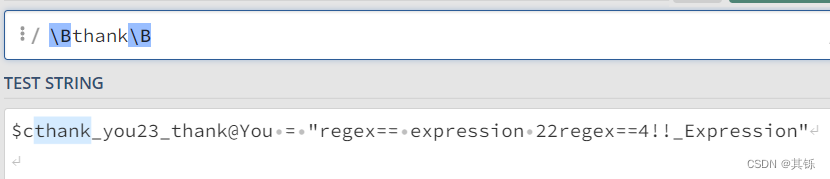
根据两个\B,目标的 thank 左右两侧应该都是\w
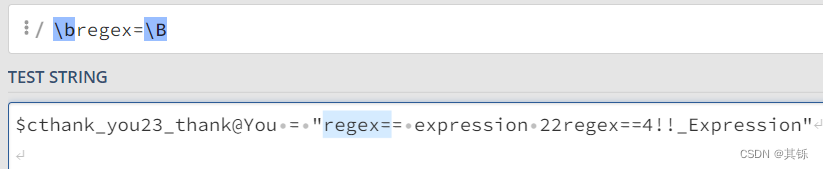
根据\b,r左侧应该是[^\w];根据\B,=右侧应该是[^\w]
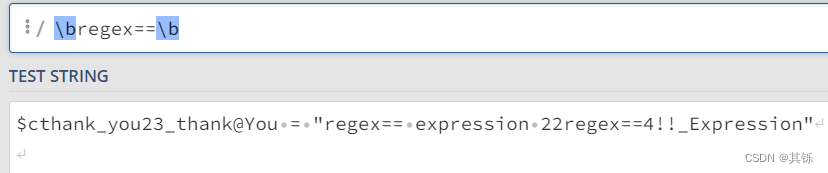
由于r是\w,根据\b,r左侧应该是[^\w];
由于=是[^\w],根据\b,=右侧应该是\w;
字符串中两个regex==均不满足左侧是[^\w],右侧是\w,因此匹配失败。
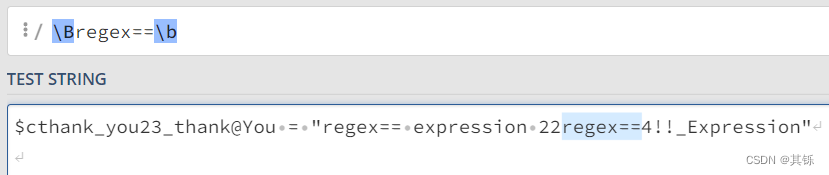
字符串中第二个regex==满足左侧是\w,右侧是\w,因此匹配成功。
上一个:python 查看包的版本
下一个:谈谈高并发系统的一些解决方案
热门文章
- Top免费VPN推荐 | 3月30日20.4M/S|免费Shadowrocket/V2ray/SSR/Clash订阅节点地址
- Top免费VPN推荐 | 3月29日18M/S|免费SSR/Clash/Shadowrocket/V2ray订阅节点地址
- Top免费VPN推荐 | 4月5日20.6M/S|免费Clash/SSR/V2ray/Shadowrocket订阅节点地址
- Top免费VPN推荐 | 3月25日19.1M/S|免费SSR/Clash/Shadowrocket/V2ray订阅节点地址
- 昆明哪里可以免费领养宠物猫(昆明市宠物猫领养)
- 重庆宠物领养平台电话号码查询地址(重庆宠物领养平台电话号码查询地址)
- Java程序查找数字的偶数因数之和
- 打动物疫苗要注意什么问题呢(动物疫苗接种时应注意哪些)
- 上海宠物医院收费标准是多少(上海宠物医院24小时)
- 谈谈高并发系统的一些解决方案